In dit artikel heb ik getest wat de toegankelijkheid tool is die het meeste fouten vind uit een grote set. Ik adviseer je op basis daarvan welke je je het beste kan gebruiken en welke combinatie van tools je het beste kan gebruiken. Deze resultaten plaats ik in een bredere context zodat je de resultaten beter op waarde kan schatten. Ik sluit af met een pleidooi om automatisch te gaan testen.

Diede Gulpers
Developer
Aangemaakt op . Laatst bijgewerkt op .
In een ideale wereld is elk platform en elke website toegankelijk voor alle bezoekers. Iedereen moet namelijk kunnen meedoen in de samenleving, en onze samenleving wordt steeds digitaler.
Omdat wij als bedrijf ook willen bijdragen aan dit ideaal ben ik gaan zoeken naar automatische tools die ons daar dagelijks, tijdens het ontwikkelen van websites, mee kunnen helpen. Willen wij elk van onze webapplicaties toegankelijk maken, dan kunnen we dat onszelf gemakkelijker maken door op een automatische manier fouten snel op te sporen.
Om deze tools te vinden heb ik een al bestaande audit uit 2016 herhaald op alle tools die ik kon vinden. Op basis van mijn test zijn Wave en ASLint de beste tools om te gebruiken om toegankelijkheid te controleren. Wave vind 39% van de gemaakte fouten. ASLint vindt er zelf 32% en helpt je om er zelf nog 19% bij te vinden, 51% in totaal. Lees de tekst hieronder als je meer wil weten over de onderbouwing van mijn oordeel.
Testresultaten
Tool |
Gevonden problemen |
Te controleren problemen |
|---|---|---|
| Wave | 39% | 39% |
| ASLint | 32% | 51% |
| ARC toolkit | 30% | 30% |
| SiteImprove | 29%` | 39% |
| AXE | 28% | 29% |
| HTML_CodeSniffer | 25% | 49% |
| Google ADT | 23% | 23% |
| Enabler | 16% | 16% |
| Nu Html Checker | 15% | 15% |
Ik heb een audit over toegankelijkheidstools herhaald om te kunnen zien welke tool het meeste fouten kon vinden. Deze tool is in 2016 opgesteld door Engelse ambtenaren. Zij hebben 142 toegankelijkheidsfouten bedacht, dat waren alle mogelijke problemen die zij zich konden bedenken.
Geautomatiseerde tools kunnen in sommige gevallen met zekerheid zeggen waar een fout zit. In andere gevallen kunnen ze je een plek aanwijzen waar een fout kan zitten. In dat geval moet een mens nog nakijken of er daadwerkelijk een fout op die plek zit. In het bovenstaande overzicht zie je dit terug in de twee categorieën “Gevonden problemen” en “Te controleren problemen”. Alhoewel je snel de conclusie kan trekken dat “Gevonden problemen” beter zijn dan “Te controleren problemen” is dit niet in alle gevallen waar. Bijvoorbeeld wil je bij een alternatieve tekst, die uitleg geeft over een informatief plaatje, niet een computer laten controleren of de informatie volledig is.
Wel is het resultaat bij “Te controleren problemen” niet evenveel waard bij elke tool. Dat komt omdat een aantal tools standaard “Te controleren problemen” lijstjes terug geeft op elke pagina. Dit is terecht, de beschreven mogelijke problemen komen op (vrijwel) iedere pagina terug. Denk hierbij aan kunnen navigeren met je keyboard voor mensen die geen muis kunnen gebruiken.
De tool HTML_CodeSniffer heeft een hoge score op “te controleren problemen”, ook ASLint en Siteimprove hebben hierop een hogere score. HTML_CodeSniffer doet dit door standaard 40 punten aan te geven die je zelf mag nakijken en krijgt zo een hoge score. In de praktijk is de kans echter groot dat je zelf de fouten niet spot. Je moet namelijk op elke pagina 40 mogelijke problemen bekijken en die worden ook nog met redelijk cryptische teksten omschreven.
Daartegenover scoren ASLint en Siteimprove “terecht” hoger.ASLint geeft je 15 duidelijk omschreven punten om te toetsen per pagina en Siteimprove 1. Beide tools maken het daarmee makkelijker voor je om gericht te controleren.
Ook zit er nog een fout in de testuitslag. Ik ben vergeten om bij de de Google ADT, de “te controleren problemen” na te lopen dus deze kan hier nog hoger scoren.
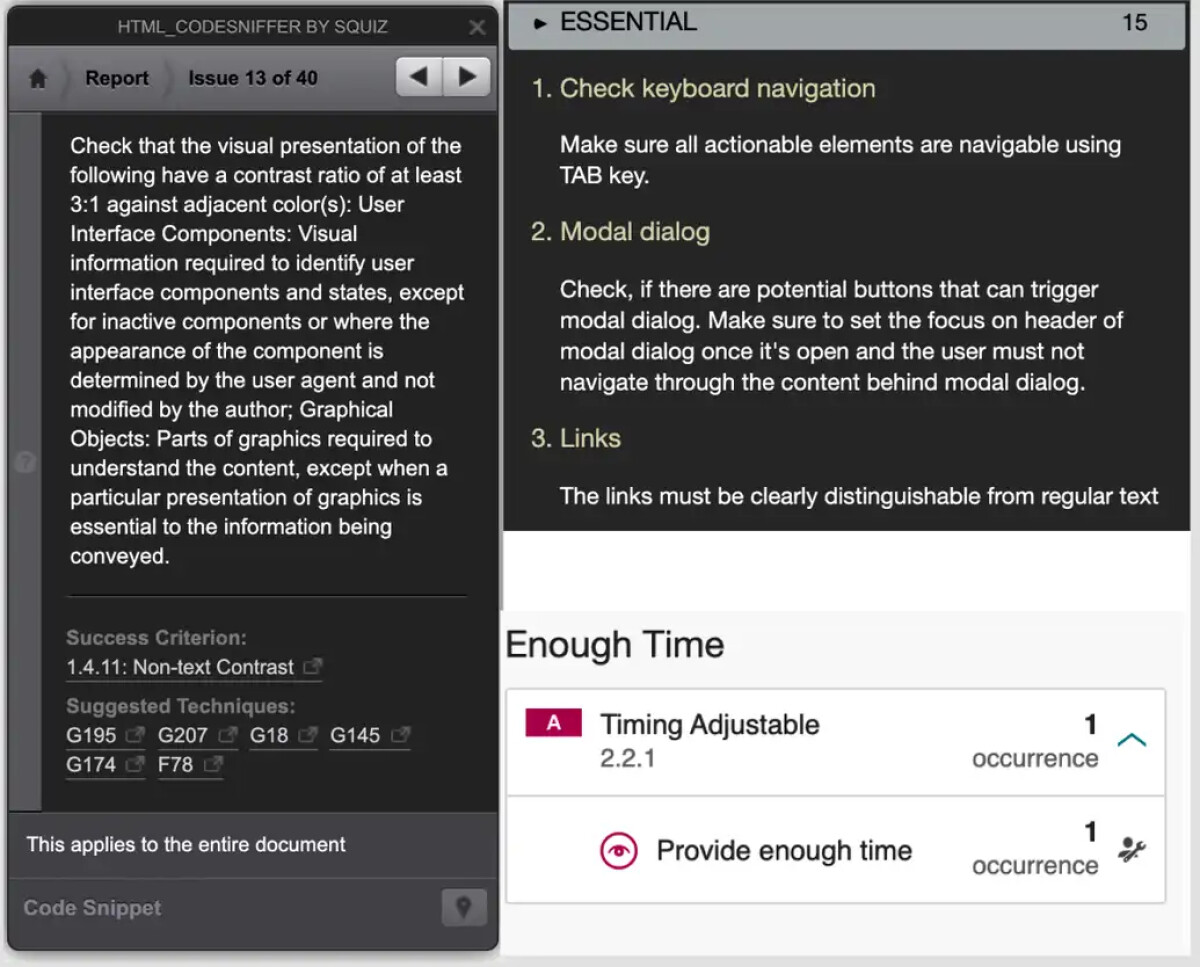
Links zie je van HTML_CodeSniffer een uitzonderlijk lange tekst over wat je zelfstandig moet controleren. Rechtsboven zie je wat ASLint zie je de makkelijkere controleacties. Bij Siteimprove heb je een korte reminder, die wel linkt naar een lange uitleg, maar ze geven maar 1 standaard nakijk punt.
WCAG tools voor CI
Wij als applicatie ontwikkelaars werken vanuit het CI gedachtegoed. CI staat voor Continu Integreren, en focust op het verkleinen van software fouten door het makkelijk te maken om doorlopend een centrale en foutloze versie van de software gedeeld te houden in het team.
Om een foutloze versie te behouden wordt elke wijziging die een van onze collega’s maakt aan de software gecontroleerd. Elke wijziging wordt door computers automatisch gecontroleerd op veel voorkomende fouten. Sets aan wijzigingen bundelen we wanneer we een onderdeel van de applicatie klaar hebben. Hiervan vragen we een collega om dit te controleren.
De door mij geteste toegankelijkheidstools bieden allemaal de mogelijkheid om deze automatische controles uit te voeren. Omdat deze controles zonder tussenkomst van mensen gedraaid kunnen worden hoeven wij geen keuze te maken in welke tool we gebruiken en kunnen we ze ook naast elkaar draaien.
Mijn advies is dan ook om Wave, ASLint en Axe naast elkaar te draaien als minimale set. Zoals je in de onderstaande tabel terug ziet kan je hiermee 61,54% van de 142 mogelijke fouten opsporen. Deze set kan je uitbreiden met HTML_CodeSniffer, Enabler en Nu Html Checker, die allen in de marges iets bijdragen aan het vinden van fouten.
ARC toolkit en Siteimprove ontbreken uit dit advies op basis van kosten. Voor gebruik vanWave, ARC toolkit en Siteimprove worden kosten gerekend wanneer je deze geautomatiseerd draait. Je kan er dus ook voor kiezen om ARC toolkit of Siteimprove te draaien in plaats vanWave. Hoe dit de totale percentages beïnvloedt heb ik nog niet berekend.
Tool |
Percentage gevonden fouten gecombineerde tools |
Percentage extra gevonden fouten |
|---|---|---|
| Wave | 39% | - |
| ASLint | 56,61% | +17,61% |
| AXE | 61,54% | +4,93% |
| HTML_CodeSniffer | 65,76% | +4,23% |
| SiteImprove | 68,58% | +2,82% |
| ARC toolkit | 70,69% | +2,11% |
| Enabler | 72,10% | +1,41% |
| Nu Html Checker | 72,80% | +0,70% |
De bovenstaande tabel geeft weer welk percentage aan fouten een tool nog kon vinden na het gebruik van de tools die ervoor worden genoemd Dit geeft zicht op het totale percentage fouten wat je kan vinden door alle tools achtereen te draaien. Zo geeft Wave, de eerste tool, zelfstandig 39% fouten. Wanneer je Wave draait en daarna AS Lint vind deze 17,61% fouten die Wave niet vindt. Axe vindt dan weer 4,93% fouten die ASLint en Wave beide niet vonden.
De pluspunten en tekortkomingen aan deze audit
Deze audit is geenszins onfeilbaar en daarom is het belangrijk om te benoemen wat ik zag als de pluspunten van de audit en de tekortkomingen.
Ten eerste een basaal punt. Het was de enige audit die ik een tijd lang kon vinden. Recent heb ik wel de ACT rules gevonden een groter project, waarvan de ontwikkelaars ook een erkende gerelateerde recommendation op de W3C hebben geschreven. Echter de ACT Rules bieden nu geen manier om numeriek uit te drukken welke tool beter functioneert.
Ten tweede voor mij het grootste pluspunt is dat de audit is opgezet om alle testcases te bedenken van wat toegankelijkheidsproblemen zijn. Daarmee hebben de auteurs ook problemen opgenomen waarvan ik verwacht dat software ze nooit kan vinden. Daardoor richten de auteurs op het ideaal van volledig toegankelijke websites en selecteer je eerder een tool die op dit ideaal richt in plaats van uitsluitend op de nu geldend richtlijnen. Ook richten ze niet op uitsluitend testen op bijvoorbeeld alle mogelijke fouten vinden die beoogd worden met WCAG 2.1 AA niveau richtlijnen. Dit maakt haar relevantie minder afhankelijk van een update van standaarden.
Ten derde een pluspunt van meetbaarheid. De 142 testcases stellen mij in staat om een meetbaar en vergelijkbaar overzicht te maken. Mijn gevoel zou mij eerder gestuurd hebben op Siteimprove met haar mooie UX en omdat ze vaker wordt aangeraden. Dit terwijl ze in mijn test niet hoger scoort dan ARC toolkit en Wave bijvoorbeeld.
Als laatste een technische pluspunt. De audit is prachtig ingericht om snel de resultaten te updaten. Er is een duidelijke handleiding aan hoe je toevoegt op het project en je hoeft op maar een paar plekken de data Òaan te passen om de resultaten te verwerken en daarmee alle rapporten te updaten.
Dan de tekortkomingen. Sommige tekortkomingen zijn trouwens niet uniek voor deze audit, maar gelden voor elke audit.
Ten eerste, de audit heeft alleen testcases voor statische HTML en CSS. Het dynamisch toevoegen van informatie aan een pagina nadat hij is geladen, zoals bijvoorbeeld liveblogs van nieuwssites of chatberichten in een gesprek, zit niet in de testcases. Deze dynamische effecten zijn een steeds groter onderdeel van het hedendaagse web. En dus is het ook wenselijk om een tool te kiezen die deze fouten kan vinden. Deze kritiek is al op het originele artikel geplaatst door Wilco Fiers , een accessibility onderzoeker.
Ten tweede tekortkoming is dat de 142 testcases geen complete lijst vormen van alle fouten die je kan maken op het gebied van toegankelijkheid. Tools kunnen dus lager scoren terwijl ze juist op niet geteste gebieden veel zouden vinden. Ook zijn de resultaten van de test niet gewogen en zijn er niet evenveel testcases per categorie. Daardoor zijn er 11 punten te scoren voor het vinden van fouten op tabellen en maar 1 punt voor het vinden van layout fouten. Als er in de praktijk eigenlijk veel meer fouten op layout mogelijk zijn dan wordt de tool dus ondergewaardeerd. Als 5 van de 11 punten praktisch altijd met dezelfde test gevonden kunnen worden, wordt een tool overgewaardeerd.
Met input van Jeroen Hulscher, een toegankelijk specialist die veel voor overheden werkt, blijkt dit niet alleen een theoretisch probleem. Hij werkt met Siteimprove waarbij hij in zijn selectie heeft gekeken naar de hoeveelheid tests die elke tool uitvoert. Zelf gaf hij het al aan, ook dat geeft geen volledig beeld. Wel zet het mij aan het denken. Siteimprove vind op deze 142 cases maar 29% fouten, dus de kans is aanwezig dat deze set aan testcases veel mogelijke fouten over of ondervertegenwoordigt, of ze zelf helemaal niet bevat.
Ten derde is de software van de audit wat achterhaald. De basisopzet van elke testcase is onderhand ouder geworden waardoor elke tool er fouten in vindt. Ook draait de audit op verouderde software pakketten die nu veiligheidswaarschuwingen geven. Dit zijn problemen die pas spelen wanneer je gebruikersinput toestaat, dus een direct probleem vormt het niet. Wel zal er gemonitord moeten worden of er andere risico’s de kop opsteken.
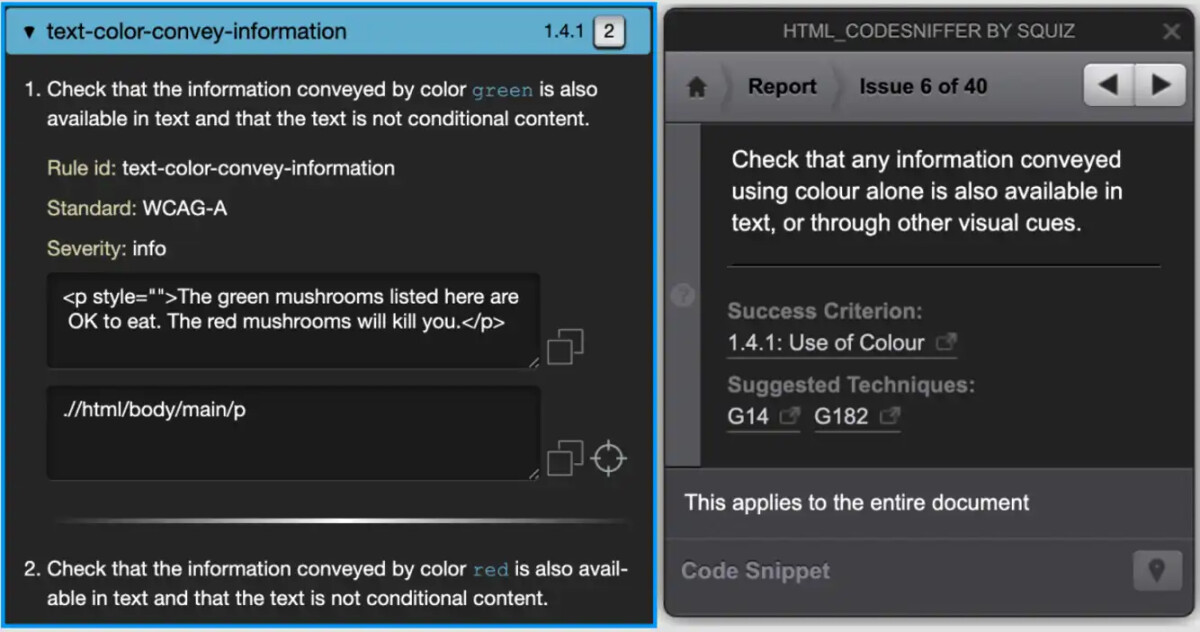
Als laatste een is er bij elke audit de last van menselijke interpretatie. Ik heb een aantal punten die al aangemerkt werden als “te controleren probleem” verschoven naar “gevonden” door de resultaten die ik zag. Omdat ik geen contact heb met de auteurs weet ik niet of de tool nu ook een ander resultaat geeft of dat ik het anders interpreteer. Ook zijn meldingen voor controle soms zo specifiek dat ik ze toch als een “gevonden” melding zie. Dat komt omdat de ene tool heel gericht een melding maakt waar de ander (te) breed blijft. Bijvoorbeeld je mag nooit alleen informatie overdragen door middel van kleur alleen. De testcase daarvoor heeft bijvoorbeeld de namen van giftige paddestoelen rood gemaakt.ASLint geeft hierop een gerichte foutmelding, omdat die de “kleurwoorden” rood en groen ziet. Ook wijst de tool specifiek aan om welke zin het gaat. HTML_CodeSniffer daar tegenover zegt op elke pagina: “Check that any information conveyed using colour alone is also available in text, or through other visual cues.”
De risico’s van automatisch testen
Je code geautomatiseerd op toegankelijkheid testen is geen onomstreden onderwerp. Het meest besproken probleem voor toegankelijkheid is dat geautomatiseerde tools maar een percentage van de totale hoeveelheid fouten kan vinden.
Dat wordt prachtig geïllustreerd doorJules Ernst, een toegankelijkheidonderzoeker, op deze pagina: /99percent/. Die bevat een flinke fout, een onleesbare tekst, op een webpagina die voor de rest helemaal toegankelijk is. Er zijn echter maar weinig tools die dit probleem kunnen waarnemen. En alhoewel dit probleem sinds vorig jaar door een aantal tools word gespot, blijft het voorbeeld sprekend: een tool kan een pagina als (bijna) foutloos beoordelen terwijl het een gedrocht is voor een mens.
Naast problemen met de dekkingsgraad kunnen er ook problemen zijn met het gegeven resultaat. Een gemeld probleem kan vals positief of vals negatief zijn. Een probleemmelding is vals positief als er wordt gezegd dat er een fout is, die er niet is. Een probleem is vals negatief wanneer er gezegd wordt dat er geen fout is, terwijl er wel een fout is.
Een vals negatief verwar je al snel met het idee dat een tool een type fout helemaal niet kan vinden. Er is echter een verschil. Van de meeste automatische tools kan je namelijk terug vinden of ze controles uitvoeren op bepaalde problemen. Anders gezegd, ik kan uitvinden of een tool mij belooft om bijvoorbeeld het contrast te controleren. Gebruik ik een tool die geen contrast controles doet, dan weet ik dat ik dit zelf nog moet controleren. Gebruik ik echter een tool die mij belooft te controleren op contrast, en die regelmatig contrast fouten meldt dan ga je er al snel vanuit dat de tool elke mogelijke contrast fout vindt. Doet de tool dit niet in alle gevallen, dan is er sprake van een vals negatief.
Dit kan er in een rampscenario toe leiden dat je, met de beste bedoelingen, je website actief slechter toegankelijk maakt door te focussen op toegankelijkheid.
Dit zijn dus terechte zorgen vanuit toegankelijkheidsonderzoekers. Er kan een setting ontstaan waarin ontwikkelaars er vanuit gaan dat ze geen toegankelijkheidsfouten op hun website hebben omdat er geen worden gevonden, terwijl eigenlijk de automatische tool simpelweg een deel van de fouten niet kan detecteren. Dit geeft je team een vals gevoel van zekerheid over de toegankelijkheid, omdat je tool groen licht geeft voor toegankelijkheid.
Een apart probleem ontstaat wanneer je de website van iemand anders automatisch audit en zelf weinig kennis over toegankelijkheid hebt. Want eigenlijk kunnen automatische tests alleen maar een indicatie geven van een mogelijk probleem. Het simpelste voorbeeld hiervan is dat een informatieve foto zijn uitleg in de paragraaf na het plaatje heeft staan. Een scanner kan dan aangeven dat de tekst ontbreekt terwijl de tekst misschien zelfs wel beter te begrijpen is via een screenreader door de uitleg in de paragraaf te verwerken, dan als ze als losstaande tekst wordt aangeboden. Als leek kan je te snel sturen op de foutmeldingen, terwijl een ontwikkelaar op veel manieren rekening kan houden met toegankelijkheid.
Naar mijn mening is het grootste risico van automatische testen echter niet het testen zelf. Het is een situatie waarin er uitsluitend automatisch wordt getest en de problemen die een tool vindt met de eerste de beste oplossing worden omzeild. Naast dat je door de automatische tests maar een deel van de problemen vaststelt, heb je geen zicht op of je oplossing ook daadwerkelijk gebruikers helpt. Het probleem zit dan vooral in de houding van het ontwikkelingsteam. Zij werken namelijk vooral in dit geval om de kwaliteitscontrole heen, in plaats van een automatische tool te zien als een hulpmiddel om gericht kennis op te bouwen over toegankelijkheid.
Voor deze sterke kanttekeningen bij automatisch testen wil ik Jules Ernst en Jeroen Hulscherbedanken. Beide hebben in verschillende e-mails hun kanttekeningen en vakinhoudelijke kennis hierover met me gedeeld en hebben me ook aan het denken gezet.
Waarom je wel geautomatiseerd wil testen
De risico’s die hiervoor zijn beschreven zie ik als randvoorwaarden van hoe je automatisch wil testen. Je draait de test om fouten te vinden die een machine kan vinden. De gevonden fouten zijn een beginpunt om je in te lezen en vast te stellen wat de juiste oplossing is. En natuurlijk om te controleren of er wel echt een probleem is.
Als je onder die voorwaarden de tools draait kom je uit op de stelling van Erik Kroes: automatische testen kost je 0% moeite om foutmeldingen te krijgen. Dat is minder moeite dan wanneer je zelf handmatig de fouten probeert te achterhalen. Ook werkt de automatische test dan als filter, je haalt niet alle fouten eruit maar de meest voor de hand liggende komen boven water.
Op dat moment maak je dan ook gebruik van wat een computer beter kan dan een mens. Elke keer als je hem vraagt om een stuk code na te kijken doet hij dat graag en hij doet dan alle checks die hij kent. Al vraag je het hem honderd keer per dag. Hij wordt nooit moe van je vraag en vindt je nooit onzeker over de code die je schrijft.
Een andere reden om automatisch te testen is omdat het praktisch gezien de enige manier is om dagelijks de focus te houden op toegankelijkheid. Het is zeer wenselijk om ook een aantal keer je applicatie te laten nakijken door een externe specialist. Maar zelfs een specialist kan je niet vragen om dagelijks te kijken naar toegankelijkheid fouten terwijl je ze wel als ontwikkelaar dagelijks kan maken.
Verder, de noodzaak om geautomatiseerd te testen is gigantisch hoog. De staat van toegankelijkheid is bedroevend. Met geautomatiseerd dagelijks testen zien we alleen het topje van de spreekwoordelijke ijsberg, maar kunnen we wel dit topje aanpakken in plaats van helemaal niks doen. Zo is het bijvoorbeeld zo dat op dit moment 1% van de overheidssites toegankelijk is. Daarnaast is 1,9% van de miljoen meest gelinkte sites op het internet toegankelijk. Dat zijn beide groepen waarvan ik verwacht dat zij nog beter dan gemiddeld proberen toegankelijk te zijn. De toegankelijkheid van heel het internet zal lager liggen.
Voor ons is die stand van zaken reden om binnenkort dapper de automatische audits aan te gaan zwengelen op onze projecten. Hoe je dat precies doet lees je later hier op de blog.
Doorpraten over toegankelijkheid?
Ik ben een enthousiaste amateur op het gebied van toegankelijkheid en ik praat graag met je verder over hoe ik tegen dit vakgebied aankijk.
